Consider this dataset points.txt. Write a script that reads this dataset and plots the second column of the dataset versus the first column as the following,
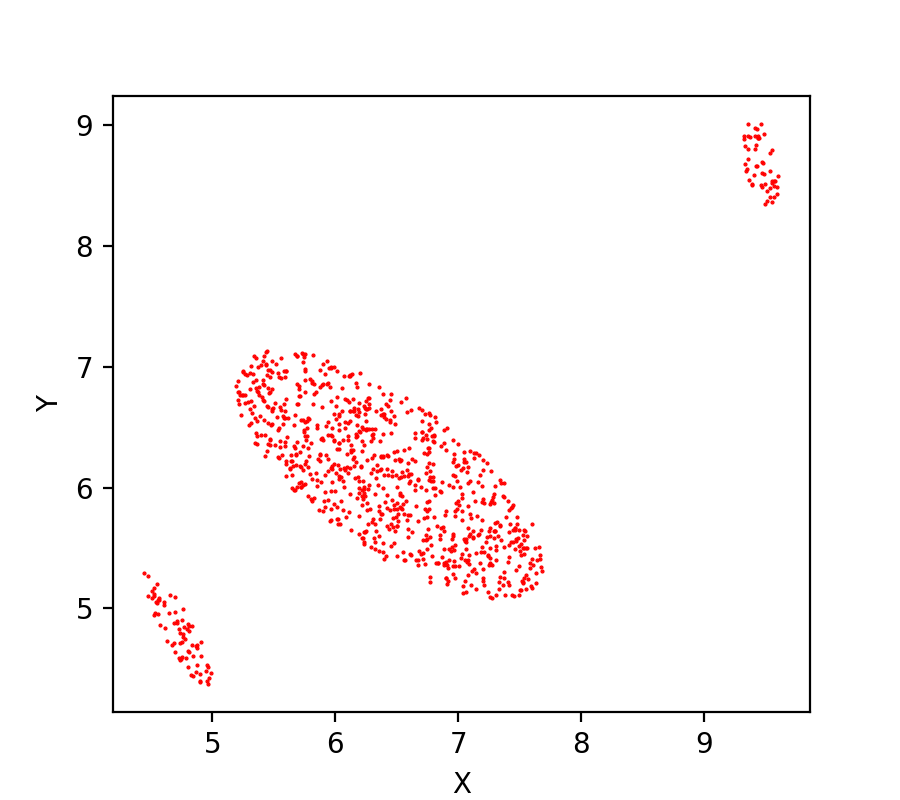
Now write another script that applies Kmeans clustering technique to this data set with an input number of clusters equal to 3.
