Consider this dataset customers.csv of a Mall’s customers containing the details of customers in a mall. Our aim is to cluster the customers based on the relevant features “annual income” and “spending score”. Write a script that reads this dataset and plots the relevant attributes of the dataset against each other like the following,
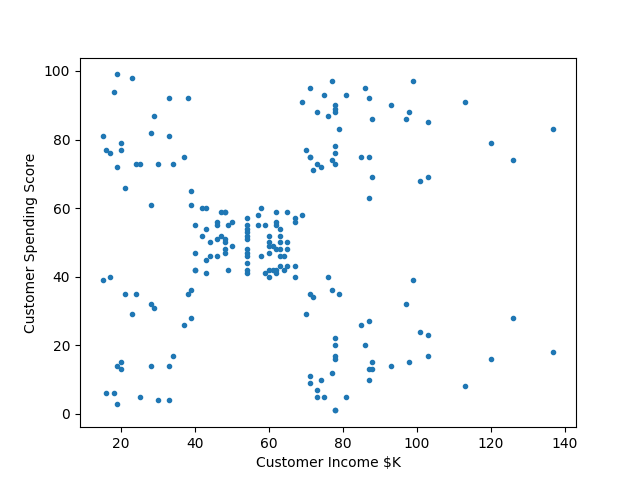
Then, the script performs K-means clustering on the two selected attributes of data with a range of number of clusters. Then use the Elbow method to find the optimal number of clusters for the customers in this dataset.
